Quick Start Selenium インストールからスクレイピングまで
ウェブページテストやスクレイピング用途でお馴染みのSeleniumについて解説します。この記事ではSeleniumの特徴や欠点、インストール方法、使い方、よくあるエラーとその対処方法について説明します。この記事を読めば大抵のSelenium操作を把握することができます。なお、言語はPythonを使用しています。
記事中でウェブページの検索結果を取得するプログラムを紹介します。
Seleniumとは
Selenium(セレニウム)はブラウザ操作の自動化ライブラリです。ウェブページのリンクのクリックや文字の入力などをプログラムから行うことができます。またウェブページ要素の取得なども行えるため、ページのテストだけでなく、スクレイピングにも使用することができます。
Seleniumの特徴
Seleniumの特徴は以下の4つです
- JavaScriptを解釈できる
- CSSやXPATHなどのセレクタで要素指定ができる
- WebDriverを使用するためブラウザ上での表示状況を確認できる
- 様々な言語に対応している
JavaScriptを解釈できる
**SeleniumではJavaScriptを解釈できます。**このため動きのあるウェブページのテストやクリックしないと表示されない要素のスクレイピングなどに使用することができます。
CSSやXPATHなどのセレクターで要素指定ができる
**SeleniumではHTML要素のセレクターとしてCSSやXPATHが利用できるため、目的の要素や属性、テキスト内容などを直接指定できます。**またXPATHを駆使すれば値の大小比較や特定の文字列の検索などが非常に簡単に行なえます。
スクレイピングの入門としてよくBeautifulSoupが引き合いに出されますが、貧弱なCSSセレクターしか使えないBeautifulSoupに比べ、SeleniumではCSSとXPATHの合わせ技により、時に簡潔に、時に複雑な要素指定をすることができます。
WebDriverを使用するためブラウザ上での表示状況を確認できる
**SeleniumはWebDriverを利用してブラウザにウェブページをロードすることができるため、ウェブページの表示状態を確認することができます。**ウェブページをテストする時に便利なのはもちろんのこと、スクレイピングする際もページの表示状態が分かることでデバッグがしやすくなります。
様々な言語に対応している
SeleniumはJava、C#、Python、Ruby、JavaScript(Node.js)などの言語に対応しています。使い慣れた言語で開発できれば、開発スピードも向上します。
Seleniumの欠点
Seleniumには以下の3つの欠点があります。
- 遅い
- WebDriver特有のエラーがある
- Waitが難しい
遅い
**SeleniumはウェブページをWebDriverにロードするため、基本的に動作が遅くなります。**もしスクレイピング用途での使用を考えていて、ウェブページのJavaScriptを解釈する必要がないのなら、BeautifulSoupかlxmlの使用をオススメします。
また動作が遅いため大規模なサイトのクロールにも不向きです。もしECサイトやニュースサイト等の大規模サイトのページ内容をスクレイピングする予定なら、Scrapyを使用することをオススメします。
WebDriver特有のエラーがある
SeleniumはWebDriverを通してウェブページをロードするためWebDriverに起因するエラーが発生することがあります。
例えばChromeDriverにはsend_keys()を利用して、サイト上に文字を入力する際に文字列の一部しか入力されないという不具合があります。
こうしたエラーに出くわした場合はデバッグの難易度が少し上がるかもしれません。
Waitが難しい
SeleniumはJavaScriptを解釈してページをロードしていますが、要素がロードされるまでの時間は基本的にユーザーが明示的にwait(待ち時間)を設定します。どの要素を待てばいいのか、waitをどのように指定すればいいのかなどは若干JavaScriptの知識を要するため、初めての場合は少し難しいかもしれません。
本記事ではwaitの指定方法もあわせて紹介していきます。
Seleniumのインストール
ここからはSeleniumをPythonで使用することを前提に解説していきます。
Seleniumをインストールするには下記コマンドを実行します。
pip install selenium
また使用するWebDriverを下記よりダウンロードします。オススメはGeckoDriver(Firefox)です。
https://github.com/mozilla/geckodriver/releases
ダウンロードしたWebDriverは/usr/binか/usr/local/binに解凍して配置してください。
Firefox以外のブラウザを使いたい場合やWindowsで動かしたい場合はこちらのリンクを参考にしてください。
Seleniumの使い方
ここからはhttps://www.python.org/を題材に、実際にコードでSeleniumの使い方を見ていきます。動作を見ながらコードが書けるのでIPythonやJupyterを使って書くことをオススメします。
ブラウザを開く
まずはURLにアクセスしましょう。下記コードでURLに指定したページをブラウザで開けます。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.python.org")
webdriver.Firefox()でWebDriverのインスタンスを作り、driver.get()で指定したURLにアクセスしています。
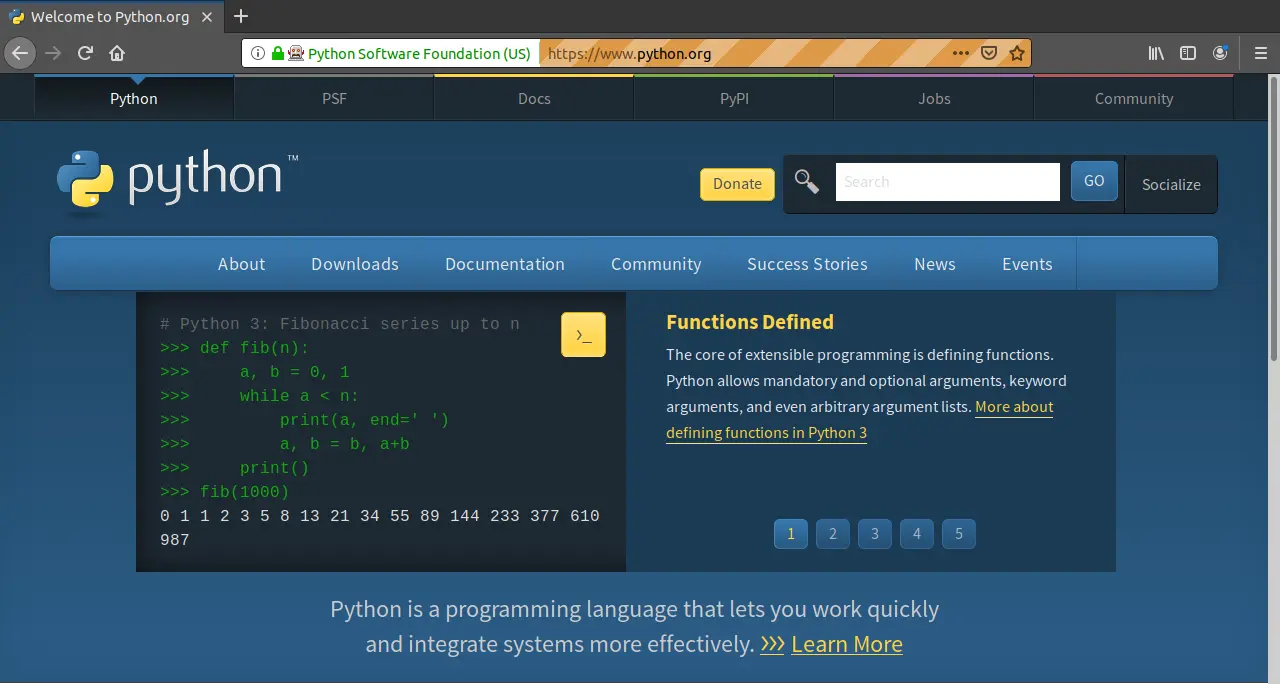
上手くいけば、画像のようにpython.orgにアクセスできます。
要素を取得する
**要素を取得するにはfind_element...()を使います。**ここではCSSセレクターを使って、Python.orgの検索窓を指定します。
検索窓の上で右クリックして、「検証」を選択すると検索窓のHTMLを見ることができます。
<input id="id-search-field" name="q" type="search" role="textbox" class="search-field" placeholder="Search" value="" tabindex="1">
input要素でIDがid-search-fieldであるものを指定すれば上手くいきそうです。この場合のCSSセレクターは
**input#id-search-field**
のように書けます。
search_box = driver.find_element_by_css_selector('input#id-search-field')
print(search_box) # <selenium.webdriver.firefox.webelement.FirefoxWebElement (session="...", element="...")>
要素の指定は要素名(find_element_by_name)、クラス(find_element_by_class_name)、ID(find_element_by_id)、CSSセレクター(find_element_by_css_selector)、XPATH(find_element_by_xpath)などから行えます。
find_element...()メソッドは最初にヒットした要素を返します。もし、複数の要素を同時に取得したい場合はfind_elements...()メソッドを使います。この場合、ヒットした要素のlistが返ってきます。例えばこんな感じです。
small_widgets = driver.find_elements_by_css_selector('div.small-widget')
for small_widget in small_widgets:
print(small_widget) # <selenium... <selenium... <selenium... <selenium...
要素の指定にはCSSセレクターとXPATHが便利です。覚えておいて損はありません。最初に手を付けるなら、簡単で手軽に書けるCSSセレクターがオススメです。【初心者向け】CSSセレクタとは?セレクタの種類や指定方法を解説!(基礎編)が参考になりました。XPATHに関してはクローラ作成に必須!XPATHの記法まとめが参考になります。
要素の存在を確認する
Seleniumは存在しない要素にアクセスしようとすると下のようにNoSuchElementExceptionの例外を出します。
driver.find_element_by_css_selector('hoge')
selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: hoge
存在が不確定な要素にアクセスする時は次のように、NoSuchElementExceptionに対して、例外処理をします。
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
driver = webdriver.Firefox()
driver.get("http://www.python.org")
try:
hoge = driver.find_element_by_css_selector('hoge')
hoge.click()
except NoSuchElementException:
print('no hoge')
# no hoge
要素が存在するはずなのにNoSuchElementExceptionが出てしまうという場合は、要素が描画される前にアクセスしてしまっている可能性があります。後述するwaitで待ち時間を指定することで要素が選択できるようになります。
文字を入力する
文字を入力するにはsend_keys()を使います。
ページが遷移してしまっている場合は次のコードでpython.orgを開いてください。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.python.org")
次の例では検索ボックスにAWSを入力しています。
search_box = driver.find_element_by_css_selector('input#id-search-field')
search_box.send_keys('AWS')
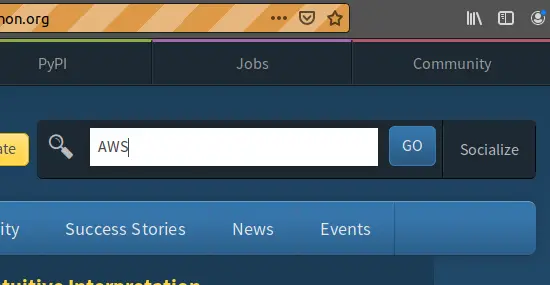
画像のように検索ボックスにAWSが入力されれば成功です。
クリックする
Seleniumでは要素をクリックするメソッドも用意されています。**click()を使って要素をクリックできます。**次の例ではGOボタンをクリックして検索を実行しています。
search_button = driver.find_element_by_css_selector('button.search-button')
search_button.click()
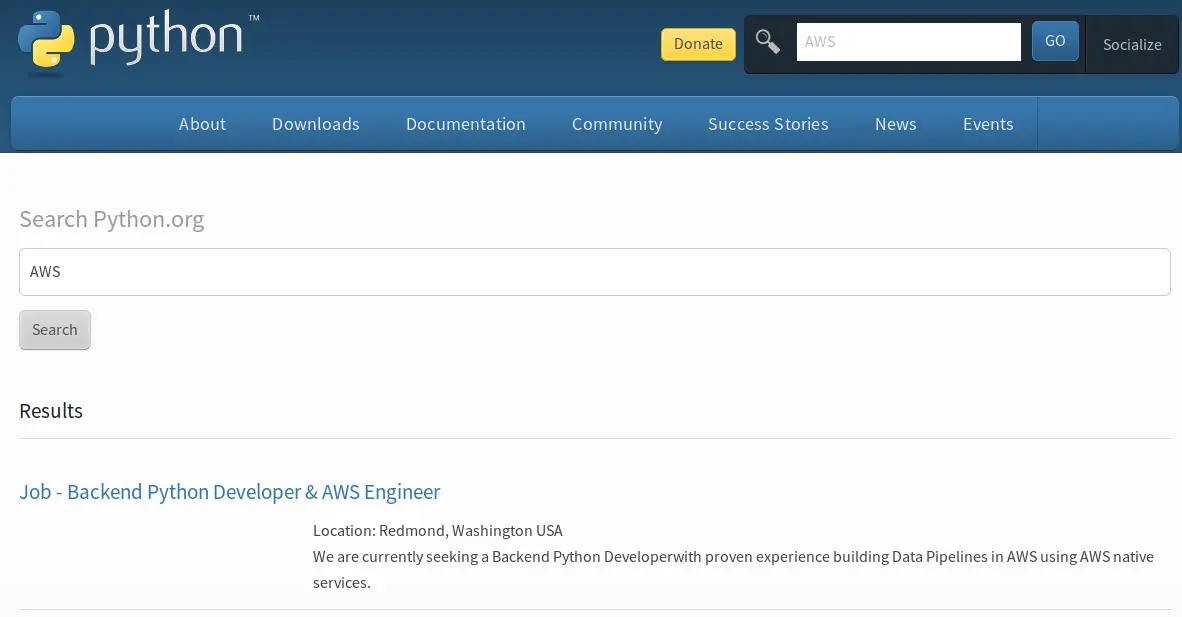
画像のようにAWSの検索結果が表示されれば成功です。
キーを押す
Goボタンをクリックする代わりにEnterを押すこともできます。Seleniumでキー入力をするにはKeysを使います。
次の例では検索ボックスに'GCP'を入力し、Enterキーを押して、検索しています。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("http://www.python.org")
search_box = driver.find_element_by_css_selector('input#id-search-field')
search_box.clear()
search_box.send_keys('GCP')
search_box.send_keys(Keys.RETURN)
上手くいけばGCPの検索結果が表示されます。SeleniumではEnterキー以外にもカーソルキーやファンクションキーなどのキーを押すことができます。Seleniumで押せるキーはこちらから確認できます。
文字を取得する
Seleniumでタグ内の文字を取得するにはtextプロパティを使います。また属性値を取得したい場合はget_attribute()メソッドを使用します。
次の例では検索結果からタイトルとURL、場所、説明文を取得しています。
対象のHTMLは次のようになっています。
<ul class="list-recent-events menu">
<li>
<h3><a href="/jobs/4006/">Job - Backend Python Developer & AWS Engineer</a></h3>
<p>Location: Redmond, Washington USA</p>
<p>We are currently seeking a Backend Python Developerwith proven experience building Data Pipelines in AWS using AWS native services.
</p>
</li>
</ul>
まずはli要素を取得し、得られた要素に対してa要素のテキストやhref属性値、p要素のテキストなどを抽出していきます。Pythonコードは以下のようになります。
from urllib.parse import urljoin
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.python.org/search/?q=AWS")
search_result = driver.find_element_by_css_selector("ul.list-recent-events li")
title = search_result.find_element_by_css_selector("h3 a").text
url = urljoin(
"http://www.python.org",
search_result.find_element_by_css_selector("h3 a").get_attribute("href"),
)
description_text = ""
descriptions = search_result.find_elements_by_css_selector("p")
for description in descriptions:
description_text += description.text + "\n"
item = {"url": url, "title": title, "description": description_text}
print(item)
# {'url': 'https://www.python.org/jobs/4006/', 'title': 'Job - Backend Python Developer & AWS Engineer', 'description': 'Location: Redmond, Washington USA\nWe are currently seeking a Backend Python Developerwith proven experience building Data Pipelines in AWS using AWS native services.\n'}
まずsearch_resultとしてリストの中から1つのli要素を選択しました。タイトルやURLなどはこの選択した要素に対して更にセレクターを適用することによって絞り込んでいます。
urlはそのままでは'/jobs/4006/'のように相対URLになってしまうので、urllib.parseのurljoinを使って絶対パスを取得しています。urljoinの詳しい使い方はこちら。
p要素は複数存在する可能性があるため、find_elementsで取得して、要素ごとに改行をはさみながら1つの文字列に格納しています。
Waitする
「要素の存在を確認する」で触れたようにSeleniumはJavaScriptをロードするため、描画前の要素を選択しようとするとNoSuchElementExceptionが発生してしまいます。描画が遅い要素に対してはWaitを挟む必要があります。
SeleniumのWaitにはExplicit Waits(明示的な待機)とImplicit Waits(暗黙的な待機)の2種類があります。基本的にはExplicit Waitsを利用することをオススメします。暗黙的な待機は
driver = webdriver.Firefox()
driver.implicitly_wait(10)
のようにして手軽に設定できるのですが、Seleniumが行うほぼ全ての操作に対してwaitがかかってしまい、数値によっては動作が遅くなります。逆に設定する数値が少なすぎると描画までの待ち時間が足りず、NoSuchElementExceptionが発生してしまいます。早い話がImplicit Waitsは使えません。
Explicit Waitsを使うには次のようにします。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
driver = webdriver.Firefox()
driver.get("https://www.python.org")
try:
search_results = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "input#id-search-field"))
)
print("do something")
except TimeoutException:
raise
**By,WebDriverWait,expected_conditions,TimeoutExceptionをインポートします。さらにwaitしたい要素に対して、expected_conditionsのpresence_of_element_located()メソッドを使います。**このメソッドは指定した要素がページ上に存在するかどうかをチェックします。
presence_of_element_located()は指定した要素がページ上で見える状態かどうかについては考慮しません。もし、要素が表示されるまで待つ必要がある場合はvisibility_of_element_located()を使用してください。
複数の要素全てを待ちたい場合はpresence_of_all_elements_located()を使います。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
driver = webdriver.Firefox()
driver.get("https://www.python.org/search/?q=AWS")
try:
search_results = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "ul.list-recent-events li")
)
)
print('do something')
except TimeoutException:
raise
expected_conditionsには他にも様々なメソッドが用意されています。こちらから確認してみてください。
Headlessモードを使う
実行するたびにウィンドウがポップアップしてきてウザい。そんな時はheadlessモードを使います。
geckodriver(FireFox)でheadlessモードを使うには次のようにします。
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
options = Options()
options.add_argument("-headless")
driver = webdriver.Firefox(executable_path="geckodriver", options=options)
driver.get("https://www.python.org")
print(driver.title)
driver.quit()
うまく動作すればページタイトルが表示されます。
**headlessモードはwebdriverによって対応が違うので使いたいwebdriverごとに調べる必要があります。**geckodriverはこちら、chromedriverはこちらが参考になります。
JavaScriptを実行する
**SeleniumでJavaScriptを実行したい!そんなときはexecute_script()を使います。**これを使えばJavaScriptのコードをwebdriver上で実行できます。
よくあるのはページを一番下までスクロールするスクリプトです。JavaScriptのscrollToメソッドを使ってページを一番下までスクロールします。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.python.org")
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
うまくいけば、ページが一番下までスクロールされます。
JavaScriptの実行結果を得たい場合は次のようにreturnを書きます。
result = driver.execute_script("return document.getElementById('about').innerHTML;")
print(result)
# <a href="/about/" title="" class="">About</a> ...
ウィンドウを閉じる
ウィンドウを閉じるにはclose()かquit()を使います。close()でタブを閉じる。quit()で全てのタブを閉じます。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.python.org")
driver.close()
【example】 Seleniumでpython.orgの検索結果を取得する
これまで紹介したテクニックを総合して、python.orgの検索結果を得るプログラムを作ります。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from urllib.parse import urljoin
import time
from pprint import pprint
import json
URL = "http://www.python.org"
SEARCH_WORD = "AWS"
contents_list = []
# ブラウザを開き、URLにアクセスする
driver = webdriver.Firefox()
driver.get(URL)
# 検索ボックスに検索ワードを入力して検索する
search_box = driver.find_element_by_css_selector("input#id-search-field")
search_box.send_keys(SEARCH_WORD)
search_box.send_keys(Keys.RETURN)
# Nextボタンが無くなるまでループする
while True:
# ページのロードを待機する
try:
search_results = WebDriverWait(driver, 5).until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "ul.list-recent-events li")
)
)
except TimeoutException:
raise
# 検索結果を取得する
for search_result in search_results:
title = search_result.find_element_by_css_selector("h3 a").text
url = urljoin(
URL,
search_result.find_element_by_css_selector("h3 a").get_attribute("href"),
)
description_text = ""
descriptions = search_result.find_elements_by_css_selector("p")
for description in descriptions:
description_text += description.text + "\n"
item = {"url": url, "title": title, "description": description_text}
# 検索結果をlistに格納する
contents_list.append(item)
# 次のページへ移動する
try:
next_elem = WebDriverWait(driver, 2).until(
EC.presence_of_element_located(
(By.XPATH, "//div/a[contains(@href,'page')][contains(text(),'Next')]")
)
)
print("go to next")
driver.get(next_elem.get_attribute("href"))
time.sleep(1)
except TimeoutException:
print("end of search result")
break
# 結果を出力する
pprint(contents_list[:5])
print(len(contents_list))
# jsonに保存する
with open("./search_reslut.json", "w") as f:
json.dump(contents_list, f, indent=2)
driver.close()
プログラムの簡単な流れは以下のとおりです。
- python.orgにアクセスする
- 検索ボックスからキーワードを検索する
- ページから検索結果を抽出する
- Nextボタンが有れば次ページに移動し、3を行う。無ければ5を行う
- 検索結果をjsonファイルへ出力する
Nextボタンの指定だけ少しトリッキーに見えるかもしれません。今回のページのNextボタンの要素は次のように書かれていました。
<div>
<a href="?q=AWS&page=1">« Previous</a>
<a href="?q=AWS&page=3">Next »</a>
</div>
**このように要素にIDやクラスが指定されていない場合は要素内の文字列や属性などが頼りになります。**今回はdivを親に持つa要素のうち、href属性に'page'という文字列を含み、かつテキスト内に'Next'という文字列を含んでいるものを指すことでNextボタンの有無を判定しました。
//div/a[contains(@href,'page')][contains(text(),'Next')]
XPATHのcontains(haystack,needle)は第1引数に検索対象を指定し、第2引数に検索文字列を指定します。検索対象に検索文字列が含まれていれば真を返します。検索対象はタグ内の文字列ならtext()、属性なら属性名の前に@をつけて、@classや@idなどと書きます。
Seleniumでよくあるエラー
ここからはSeleniumでよくあるエラーについて紹介します。
TypeError: 'str' object is not callable
**エラー自体は文字列を関数として呼び出してしまった時に出ます。**よくあるのはtextを取得する際に誤ってtext()とメソッドで呼んだ時などでしょう。XPATHでtext()と書くだけにやりがちなエラーです。
title = driver.find_element_by_css_selector("h3 a").text()
# TypeError: 'str' object is not callable
title = driver.find_element_by_css_selector("h3 a").text
NoSuchElementException: Message: Unable to locate element
存在しない要素にアクセスした際に出る例外です。
driver.find_element_by_css_selector('hoge')
selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: hoge
もし存在しているはずの要素ならばwaitが足らないか、設定されていないのかもしれません。waitを設定して要素が描画されるのを待ちます。waitに関してはこちらに書きました。
Chromedriverでsend_keys()を使うと文字列が最後まで入力されない
記事執筆時点で、chromedriverを使って文字列をsend_keys()で入力しようとすると中途半端に入力されてしまう不具合があります。対策は3通りあります。
- Geckodriverを使う
- JavaScriptを使って入力する
- 1文字ずつ入力する
1番手っ取り早いのはGeckodriverを使うことです。Geckodriverなら正常にsend_keys()で文字列を入力できます。
JavaScriptを使って入力する方法もあります。execute_script()を使ってJavaScript越しに要素の値を書き換えます。
from selenium import webdriver
URL = "http://www.python.org"
SEARCH_WORD = "AWS"
# ブラウザを開き、URLにアクセスする
driver = webdriver.Firefox()
driver.get(URL)
input_js = f"""
let search_box = document.getElementById('id-search-field');
search_box.value = '{SEARCH_WORD}';
search_box.dispatchEvent(new Event('change'));
"""
driver.execute_script(input_js)
少し面倒ですがどうしてもchromedriverを使わなければならない場合に使えるテクニックです。
1文字ずつ入力する方法は単に文字列をforで1文字ずつに分けて入力する方法です。実行が遅くなるのであまりオススメはしません。JavaScriptを使いたくなく、Pythonのみで書きたい場合などに使えます。
下記の記事も参考になります
https://github.com/angular/protractor/issues/3196
https://stackoverflow.com/questions/40985765/selenium-send-keys-sending-incomplete-string
参考
https://selenium-python.readthedocs.io/
https://www.asobou.co.jp/blog/web/css-selectors
https://qiita.com/rllllho/items/cb1187cec0fb17fc650a
https://qiita.com/edo_m18/items/ba7d8a95818e9c0552d9
https://developer.mozilla.org/en-US/docs/Mozilla/Firefox/Headless_mode
https://qiita.com/derodero24/items/9e9567790bde9e4b9d0c
スクレイピング・クローリングに関する知識をつけるのには『Pythonクローリング&スクレイピング ―データ収集・解析のための実践開発ガイド』を使いました。コマンドを使った簡単なスクレイピングからScrapyを使った本格的なクローラーまで作れるようになった上に、それらをAWS上で運用することもできるようになりました。 2019/8/10に増補改訂版が出たため、そちらもご一読ください。